
Inside SonicDB: Faster State Access Without the Overhead

TL;DR
Sonic Labs has developed SonicDB, a database that stores accounts, balances, nonces, and values for smart contracts in binary files on the file system. It utilizes a processing speed of 1,300 MGas/s on average with SonicVM on the Sonic mainnet for the first 11 million blocks.
The key to performance in SonicDB is that we have solved the read amplification problem inherent in mainstream blockchain database implementations, which arises from the use of off-the-shelf key-value store products, such as RocksDB or LevelDB, for implementing blockchain databases. Key-value store products accelerate the time-to-market and ease code development. Still, performance deteriorates due to the need to build a Merkle-Patricia trie on top of a search tree.
Our SonicDB utilizes a novel data structure that constructs a prefix tree, which directly indexes binary data. Our implementation avoids inefficient multiple lookups present in existing blockchain database implementations.
What is a Blockchain Database?
Popular blockchains, such as Sonic, store terabytes of data in a blockchain database, often referred to as a StateDB. Blockchain data comprises millions of user accounts, each with potentially millions of transactions. As transactions are processed, the data must be persisted and maintained. This typically requires a database management system. Unlike traditional database management systems, blockchains require an additional aspect of authentication. That is, each database in the blockchain needs to provide proof of the integrity of the data it stores. This is achieved by retaining the cryptographic hash of the data and verifying that it corresponds to the original data.
In blockchains, authenticated storage commonly employs the Merkle-Patricia Trie (MPT) structure, a specific variant of the Merkle tree. Each leaf node in an MPT stores a value, and the path from the root to the leaf node corresponds to the key of the stored value. Each inner node in the MPT stores the crypto hash of the concatenated contents of all its children. Thus, the MPT’s root contains the hash that serves as the witness of the blockchain state's authentication.
The ingenuity of the MPT lies in its ability to allow the hash of the entire database (state) to be recomputed incrementally, i.e., without computing the entire hash for all data with every change to a subset of data. This is illustrated in Figure 1. The orange rectangles represent data values. The aqua circles represent partial hashes. Note that intermediate hashes are derived from existing hashes. The top hash is the world state hash. Thus, if a single value is changed, only the path leading from the root hash to the value needs to be recomputed.
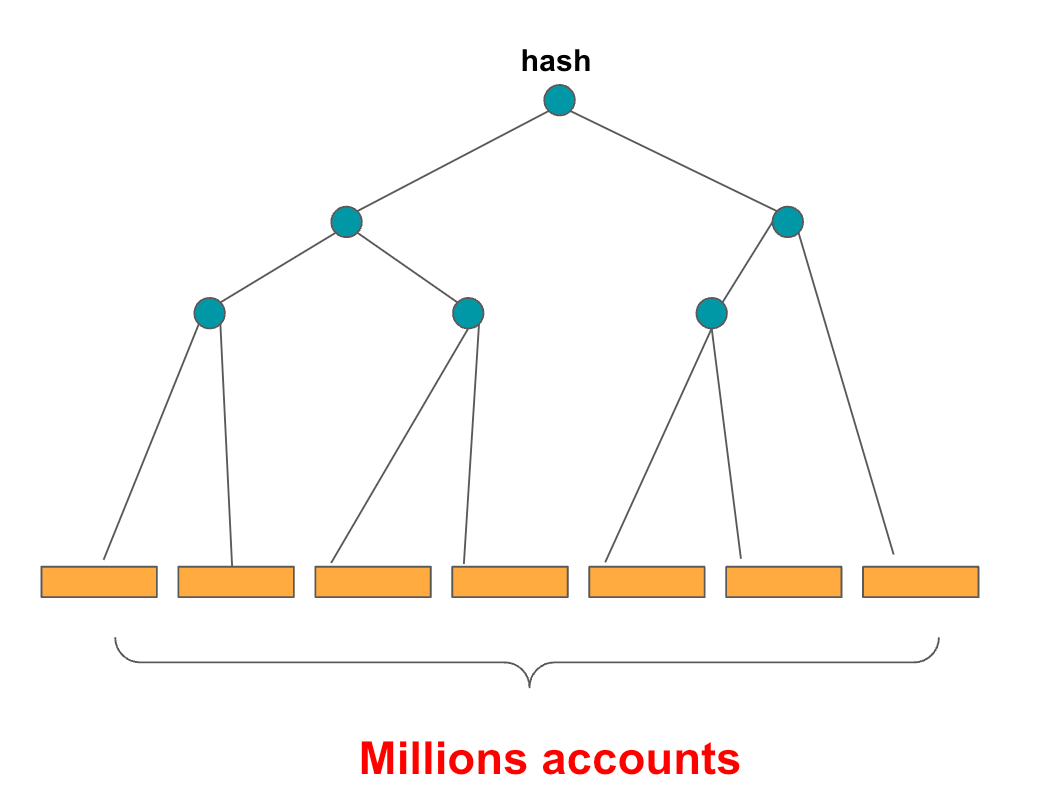
Every new transaction among millions in a blockchain modifies the MPT structure. In particular, new accounts are created. Account attributes, such as nonces and account balances, are modified, and the storage slots of smart contracts are also modified. Each of these changes must be reflected in the MPT. Additionally, relevant hashes must be modified. It means nodes of the tree representing hashes are also continuously recomputed up to the root hash. This is depicted in Figure 2, where the number of nodes (both rectangles and circles) grows over time.
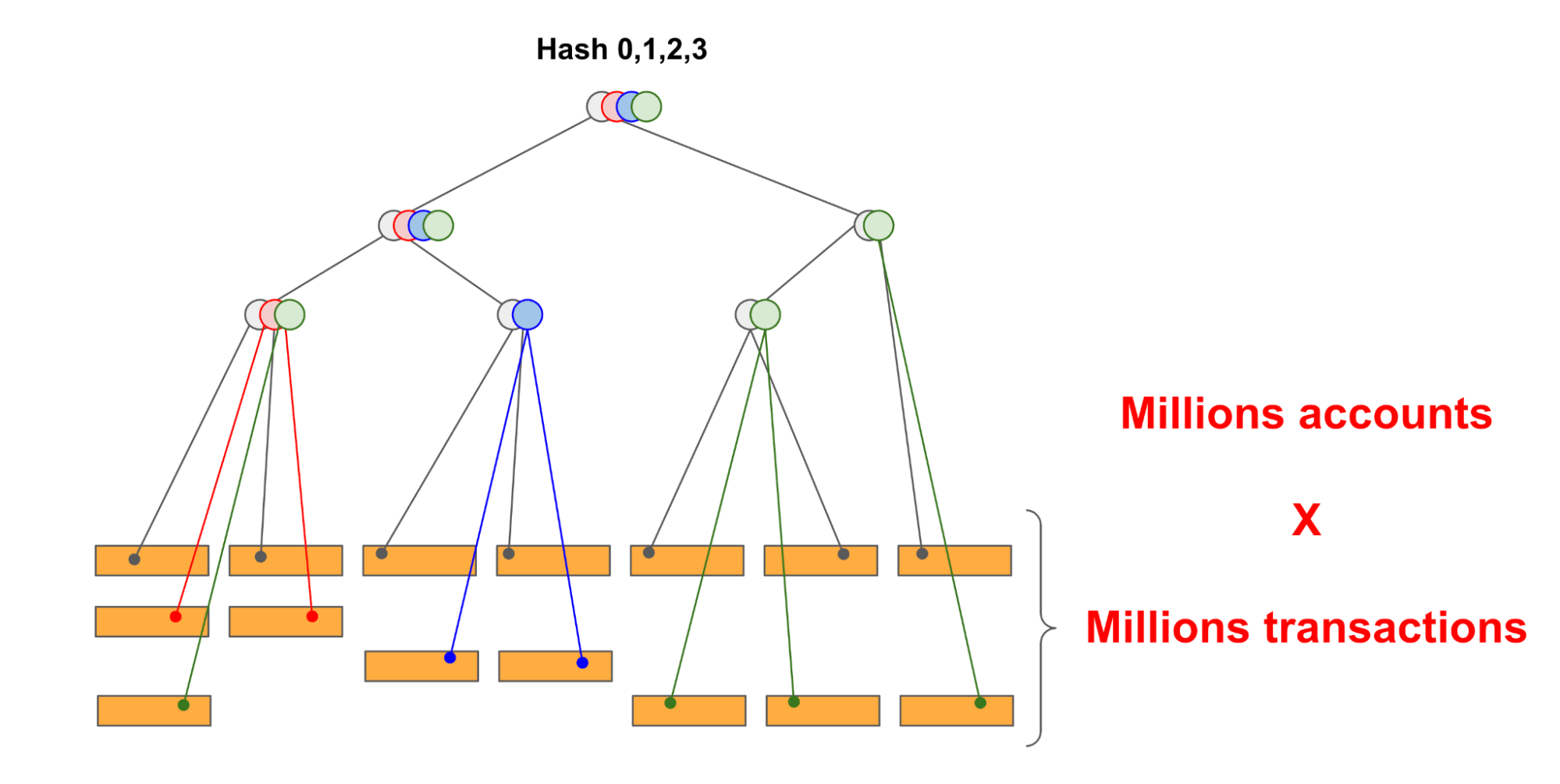
Since the volume of data in the MPT structure is vast, it cannot be stored in main memory and must be stored on disk (preferably a fast NVMe drive). Hence, most blockchain databases select a well-performing, off-the-shelf key-value database and utilize it as a backend. This was achieved through mainstream implementations of the blockchain database (known as the StateDB), such as in the Ethereum Geth client. For example, Geth implements the MPT data structure using off-the-shelf key-value store databases, LevelDB.
The Read Amplification Problem
An overlooked issue, however, is read amplification. The pre-existing databases are usually well optimized for searching data. For this, they use tree- or ordered data structures (such as B-trees and LSM trees), which exhibit a logarithmic worst-case runtime complexity for accessing data. Although this means they are very efficient for retrieving data, an issue is that the MPT builds on top of them. Following in the MPT data structure also requires visiting a logarithmic number of nodes.
To assess compound performance, we must consider the access time of the MPT and the database access time. Since both data structures are, in essence, trees, they feature logarithmic access times. In total, we must multiply these two worst-case time complexities to obtain the worst-case complexity of the overall access time.
This scenario is depicted in Figure 3. A traversal of a 3-node path to the leaf requires three queries of the underlying database, each costing O(log n) time. In general, the length of the longest path on a balanced tree is log n. Thus, we have a read amplification of O(log2 n).
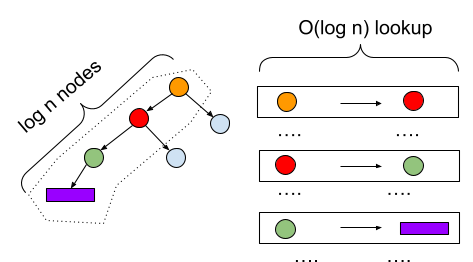
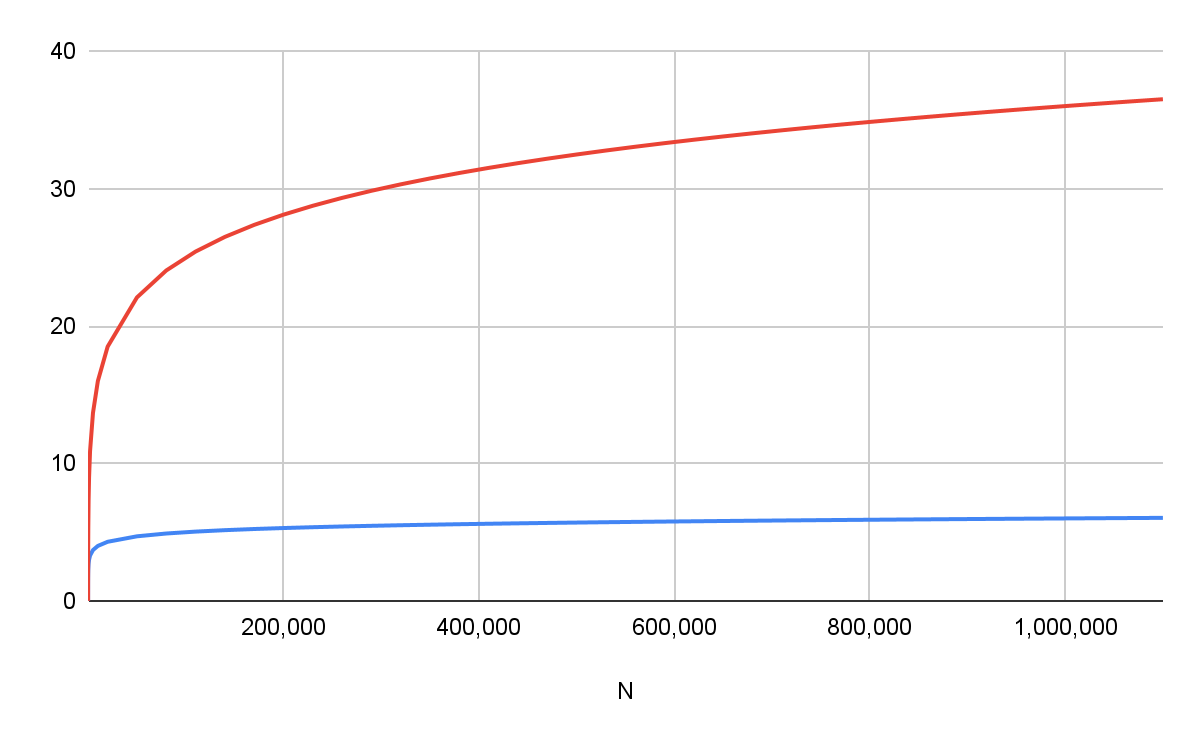
Figure 4 stylizes the read amplification problem. The overhead varies depending on the database implementation and the amount of data. To give an intuition for the read amplification problem, consider terabytes of data; the additional lookup required is approximately seven times the original, which can lead to slowdowns simply because of using a key-value store such as LevelDB/RocksDB instead of implementing a Merkle-Patricia tree directly using binary files in the file system. The blue curve represents log n function, while the red one is log2 n.
The primary reason key-value stores are not ideal is that they store and order data to support range queries for retrieving it. A data retrieval exhibits a worst-case runtime complexity of O(log(n)) in the size of the database n. However, range queries are not a necessary feature for a blockchain implementation, and we can build the MPT natively on binary files with constant access time, overcoming the read amplification problem.
A Native StateDB for High Performance
SonicDB is a native blockchain database for Sonic that stores live data directly in the file system and does not require a key-value store such as LevelDB/RocksDB. Hence, we have an access time of O(log n) instead of O(log2 n), and the read amplification problem is avoided by accessing MPT nodes in constant time using binary files. This is achieved by knowing the node's location in the file ahead of time.
The SonicDB comprises two components: an in-memory representation of the MPT structure that facilitates efficient hash recomputation, and on-disk binary files that enable constant-time lookups through direct indexing for nodes of the MPT. A lookup of a node in the MPT involves querying specific positions within the binary files if the node does not exist in a dedicated cache.
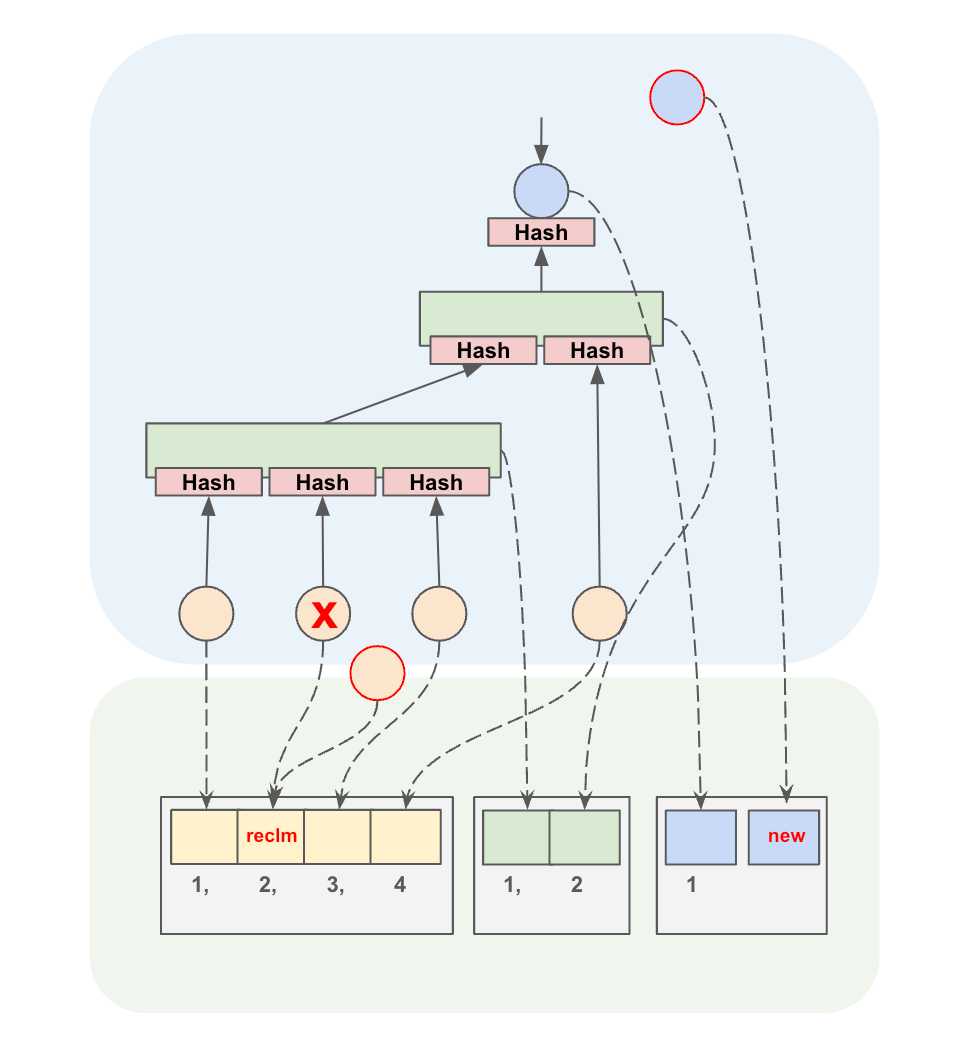
We illustrate the new data structure in Figure 5. Here, the blue area represents the in-memory representation, and the green area represents the on-disk binary files. The blue circle represents the root node with its hash, the green rectangles represent internal nodes, and the yellow circles are leaf nodes, all including their hashes. The binary file does not compact and reorganize itself. An alive node does not change its position in the file. If a node of the MPT is deleted, its data junk in the file is put into a pool and given to a new node later. If the pool is depleted, new nodes are added to the binary file at the end of the file.
Figure 5 illustrates this principle: let's assume that an update in the tree commands removal of a leaf node — see position 2 in the data file, where a node is stored. This node is removed, visualized by the red cross. At a later stage, another node is added to the tree. Since there is a space in the binary file, this space is reclaimed by the new node. Let's furthermore assume that an additional update of the tree creates a new root (the blue circle). Since there is no free space in the files, this node is appended at the end. This assures that no data has to be shifted when deleting items (so that each alive node can keep its position), and the space is either reclaimed, or the data file is expanded by appending the node at the end.
Evaluation
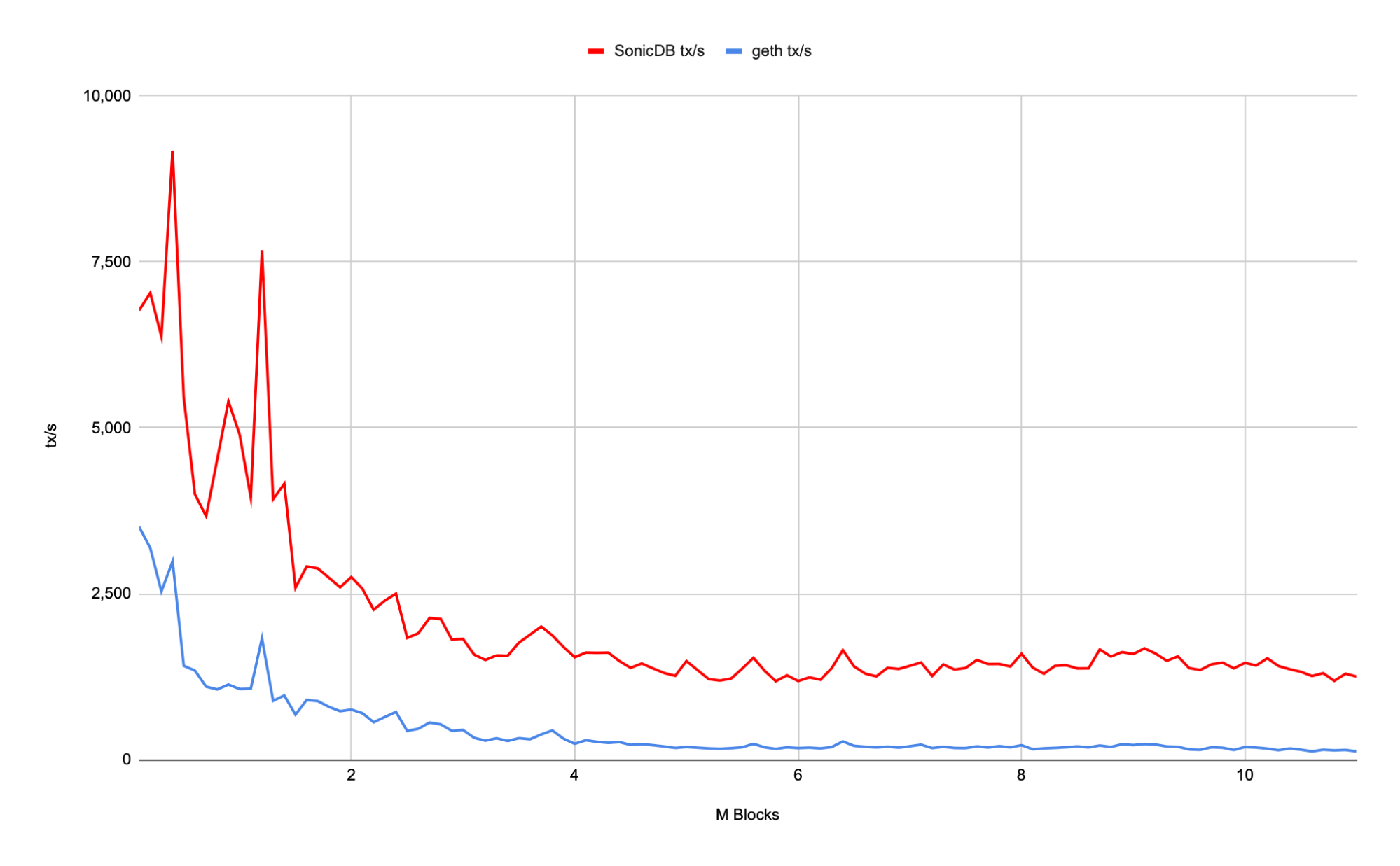
We evaluated the SonicDB by processing the first 11 million blocks of our Sonic mainnet. The block processing in isolation (without taking networking/consensus into account) achieves a rate around 1,300 MGas/s. In contrast, Geth’s block processing achieves a gas rate of 210MGas/s for the first 11 million blocks, which is 6.2x slower than SonicDB with SonicVM.
In Figure 6, we depict the throughput of both SonicDB with SonicVM (in red) and Geth (in blue) measured in transactions per second — the average transaction complexity for the first 11 million blocks of the Sonic mainnet was 348.4 KGas per transaction. In Figure 5, we see that initially, both implementations don’t access the drive at all since all data fits in their caches. When the DB sizes start to grow, data is pushed to disk, and we see an impact on the transaction throughput.
Summary
We have developed SonicDB, which avoids the read amplification problem by using binary files instead of key-value stores such as LevelDB. We use new in-memory data structures to access the data of nodes with a fixed position in binary files. The key to our design is that we avoid a double lookup into two sorted data structures and maintain a single hash-based data structure. We achieved an average gas rate of 1,300 MGas/s for the first 11 million blocks on Sonic Mainnet with our SonicDB.
In a future article, we will explore in more depth how we designed SonicDB to require significantly less storage.


